
In questo articolo mostreremo come fare un Cluster Proxmox con Ceph direttamente dall’interfaccia grafica, come installare il pacchetto di Ceph e la sua prima configurazione.
1. Cluster Proxmox a 3 nodi
Vai su Datacenter > Cluster e clicca su Create Cluster
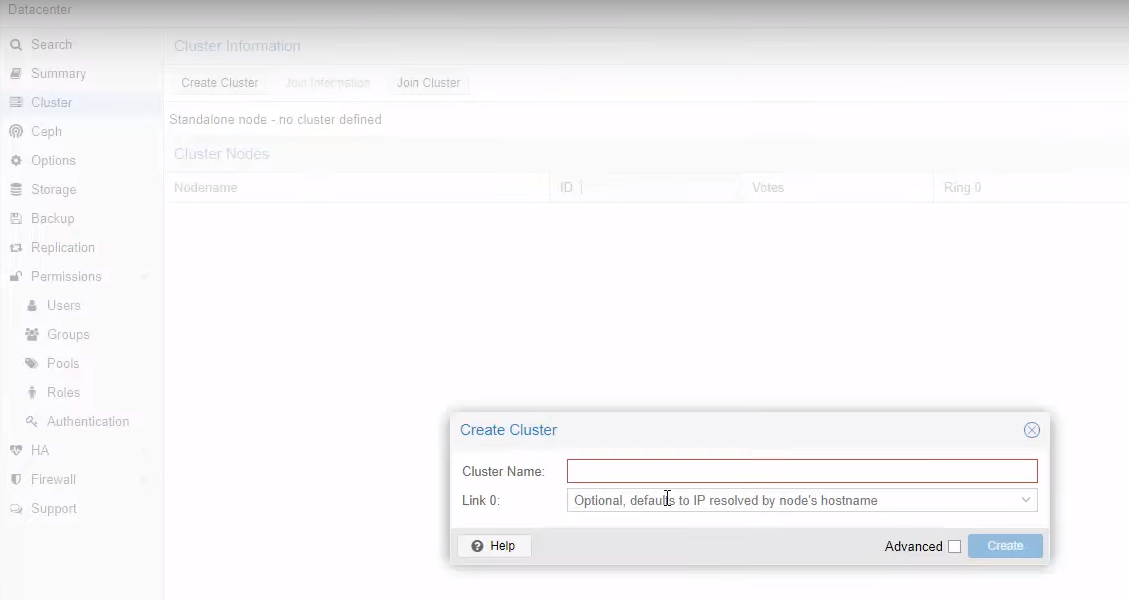
Dare un nome al Cluster che si sta per creare, poi scegliere l’interfaccia dedicata, e poi il bottone Create.
Nota: In ambiente di produzione è sempre doveroso, ma non obbligatorio, separare l’interfaccia di Cluster dalle altre interfacce (soprattutto quella di Ceph).
E’ meglio avere un’interfaccia per il Cluster, un’interfaccia per Ceph, e una per l’amministrazione GUI, separate da quelle dedicate alle VM e/o container per tenere il tutto pulito e non incorrere in eventuali problemi di performance.
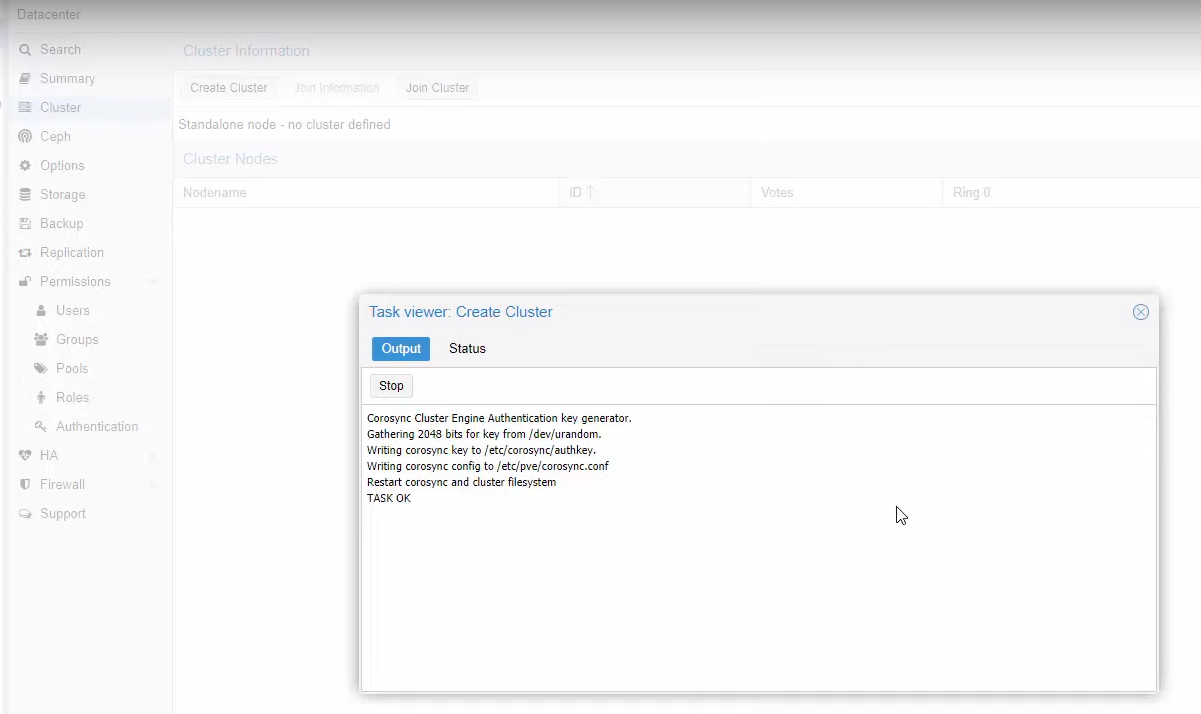
Alla termine della procedura, vedrete una finestra simile a quella sotto. Il Cluster è quindi creato, non resta che aggiungere gli altri nodi.
Cliccare ora sul bottone Join Information e poi sul bottone Copy Information.
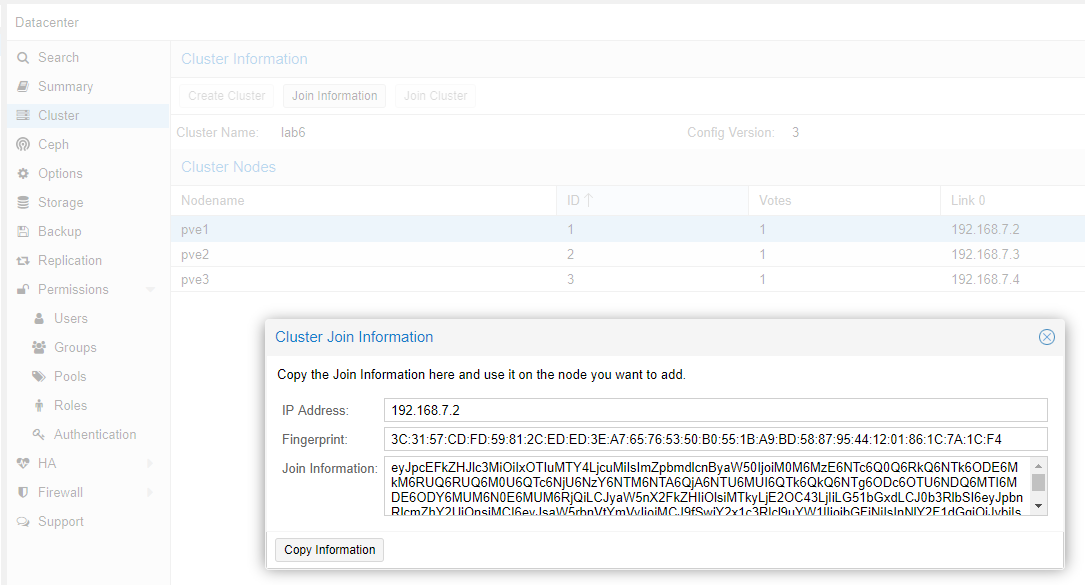
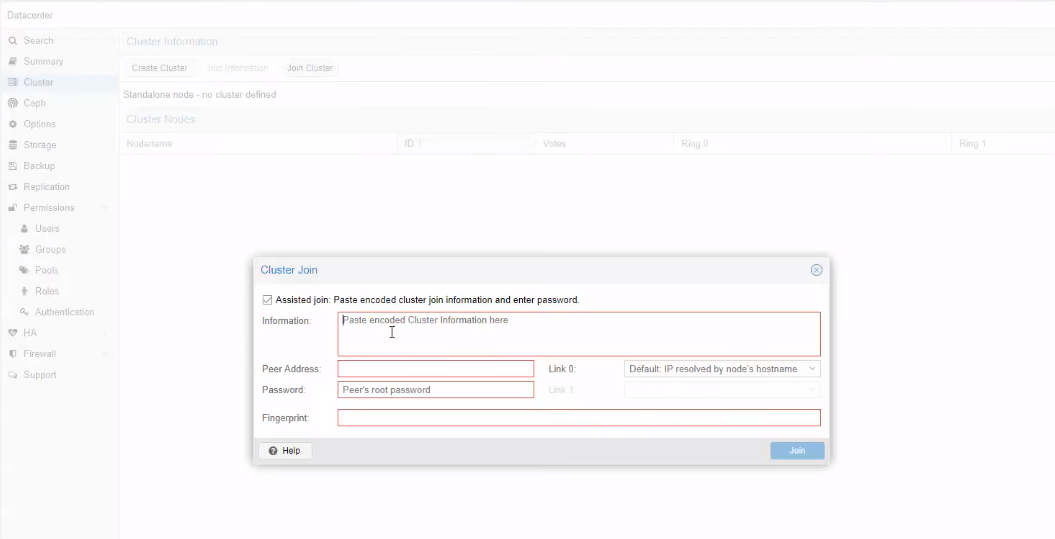
Spostatevi su ogni altro nodo che volete inserire, e sempre dal medesimo percorso (Datacenter –> Cluster) cliccate su Join Cluster, e incollate il contenuto inserendo gli eventuali valori mancanti.
Abbiamo, inoltre, eseguito l’aggiornamento dei pacchetti, sempre dall’interfaccia grafica, e poi – come sempre – abbiamo installato alcuni pacchetti base Debian che ci tornano utili per eventuali troubleshooting.
# apt install htop iotop
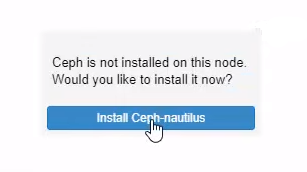
2. Ceph: installazione e setup
Anche per installare Ceph abbiamo utilizzato la comoda interfaccia grafica. Seleziona ogni nodo del cluster, poi spostati su Ceph e clicca sul bottone Install Ceph-nautilus
Clicca sul bottone Start Installation
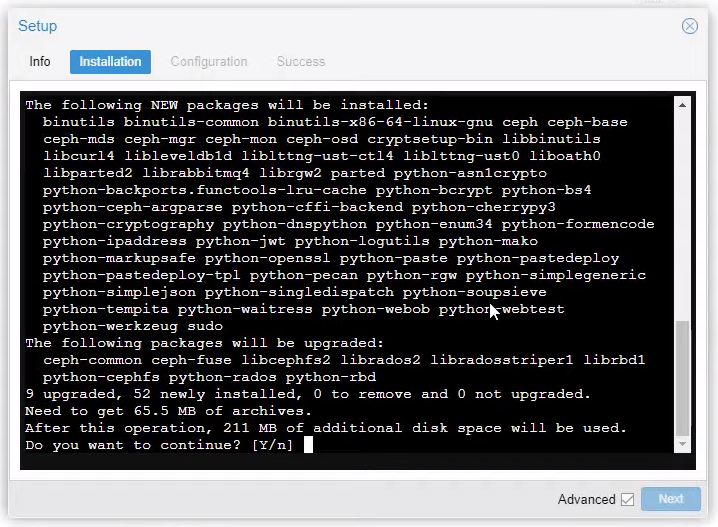
Poi digita Y e dai invio
Sebbene lo scopo di questo articolo non sia un approfondimento di Ceph (per il quale vi rimandiamo alla pagina di Help ufficiale che trovate al fondo di questo articolo, per avere maggiori dettagli sui parametri di configurazione), spenderemo qualche minuto per introdurre velocemente i parametri di questa pagina (che vedete sotto) che comparirà durante la procedura di installazione.
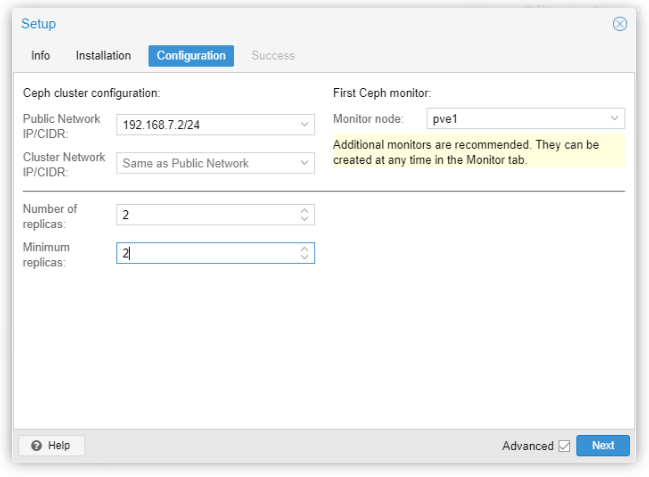
Public Network: è necessario configurare una rete dedicata per Ceph, l’impostazione è obbligatoria.
Ti consiglio di separare il traffico Ceph dal resto come, ad esempio, la comunicazione del cluster che, se non viene eseguita, può ridurre le prestazioni di Ceph.
Cluster Network: facoltativamente si può anche separare la replica OSD, e il traffico di heartbeat. Questo alleggerirà la rete pubblica (Public Network) e potrebbe portare a significativi miglioramenti delle prestazioni soprattutto nei grandi cluster.
Number of replicas: definisce la frequenza con cui un oggetto viene replicato
Minimum replicas: definisce il numero minimo di repliche richieste per l’I/O, da contrassegnare come complete.
In questo lab, e per lo scopo di questo articolo, la rete Ceph non è separata dal resto!
Inoltre è obbligatorio scegliere il primo nodo monitor.
Se tutto è andato bene dovresti vedere una pagina di successo, come quella della figura sopra, in cui ci sono ulteriori istruzioni su come procedere.
Ora sei pronto per iniziare a utilizzare Ceph, ma dovrai prima creare i Monitor aggiuntivi, alcuni OSD e almeno un Pool (come si legge dentro!).
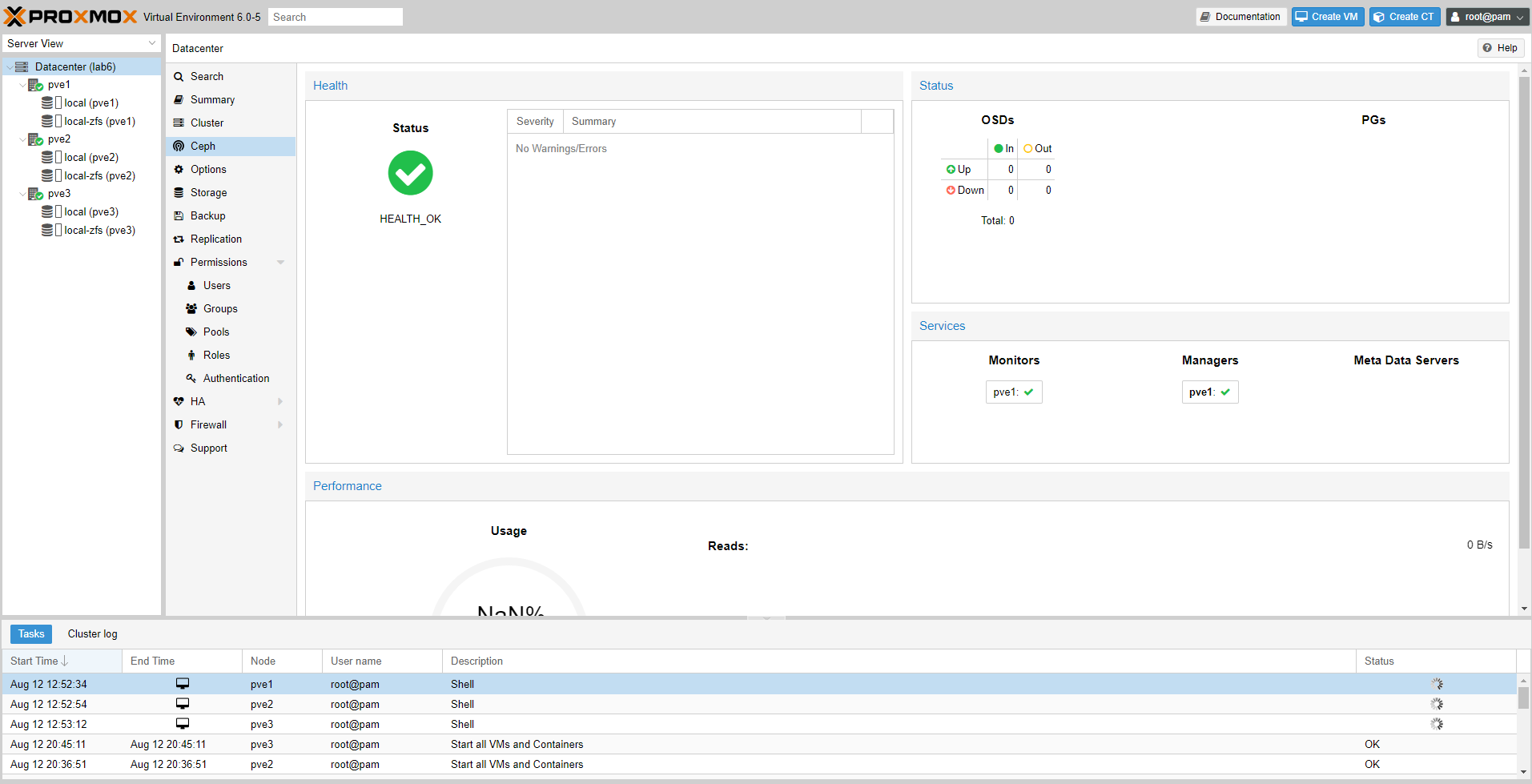
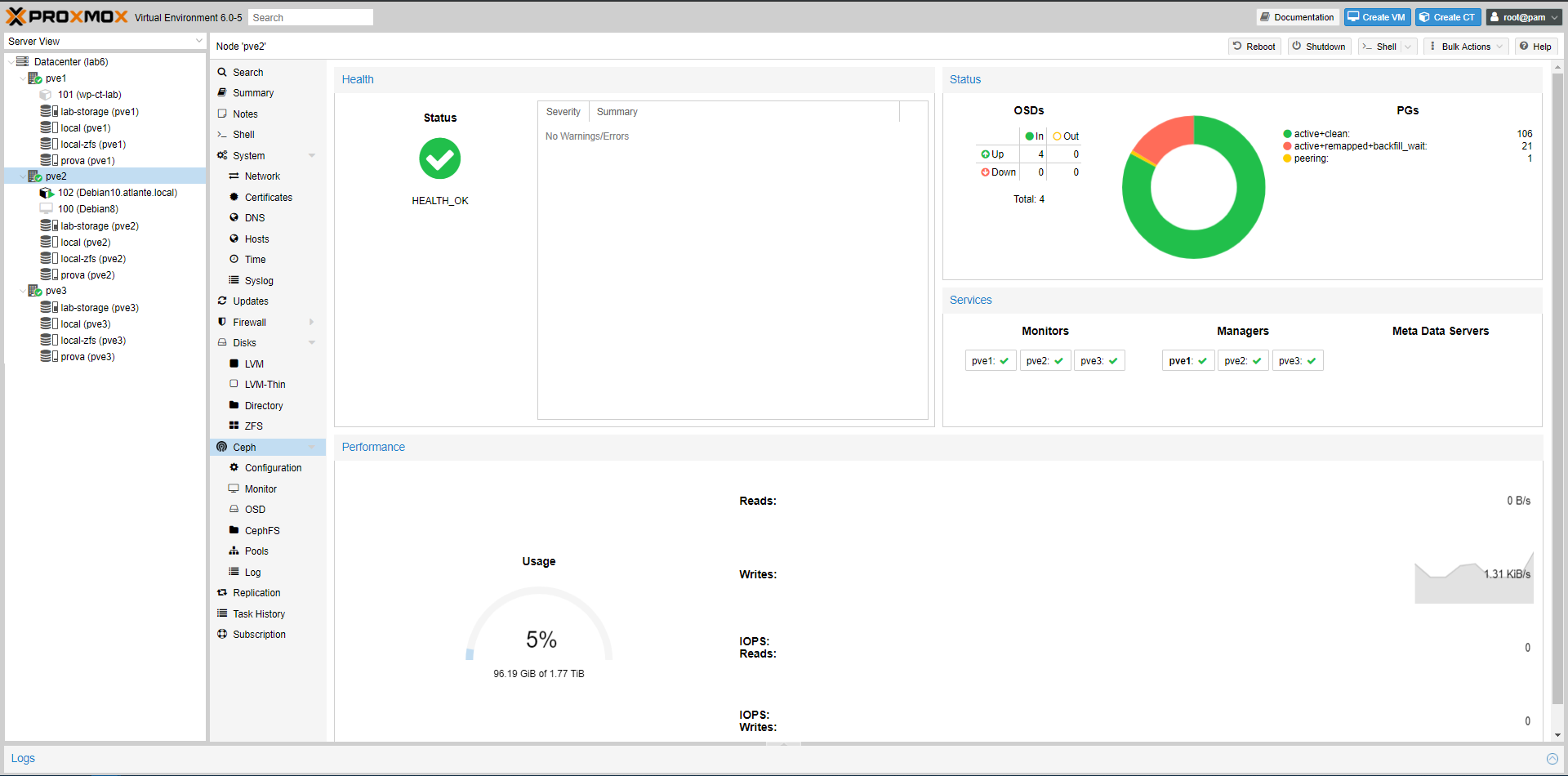
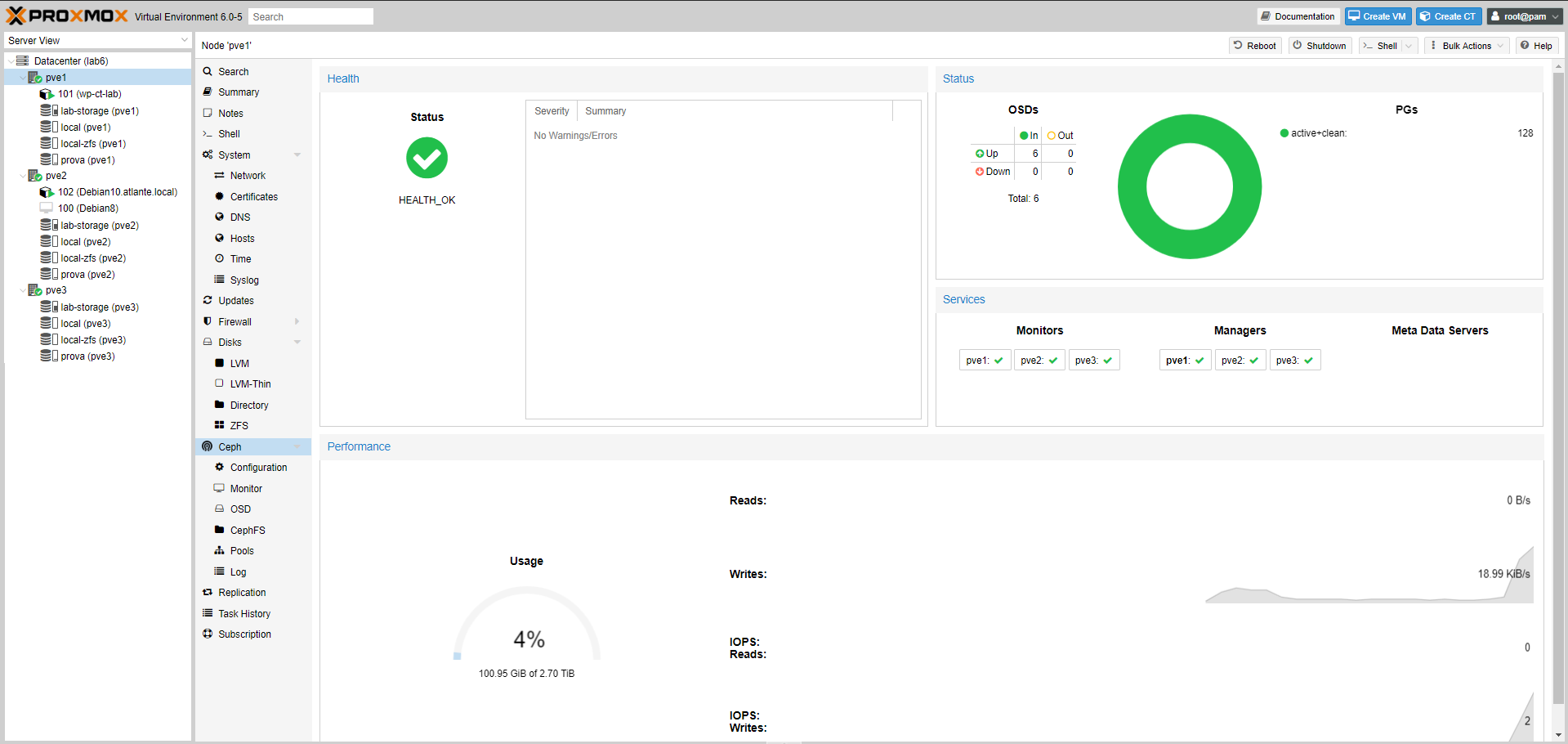
Aprendo la pagina di status si potrà vedere immediatamente (grazie all’intuitivo uso dei colori e delle icone) se tutto va bene oppure no.
Nell’immagine seguente il colore verde ci suggerisce a colpo d’occhio lo stato di salute, e se guardate un po’ meglio nella colonna OSDs noterete che non ci sono ancora dischi (OSD).
Vediamo insieme nel prossimo passaggio come creare un OSD da un disco.
3. Ceph: creazione OSD
Selezionate un nodo del cluster, poi Ceph e ancora OSD.
Cliccate su Create: OSD comparirà la finestra di seguito in cui potrete inserire tutti i dischi che desiderate, e impostare alcuni parametri.
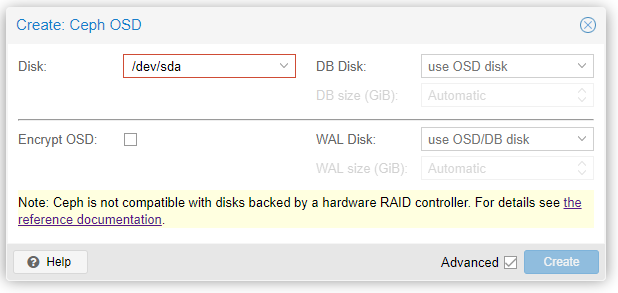
NOTA
In questo lab, abbiamo scelto inizialmente di inserire dentro Ceph solo il primo SSD (da 480GB) per ogni server; questa scelta per simulare una situazione in cui si ha la necessità di aumentare lo spazio storage in ambienti di produzione.
Di seguito il risultato finale.
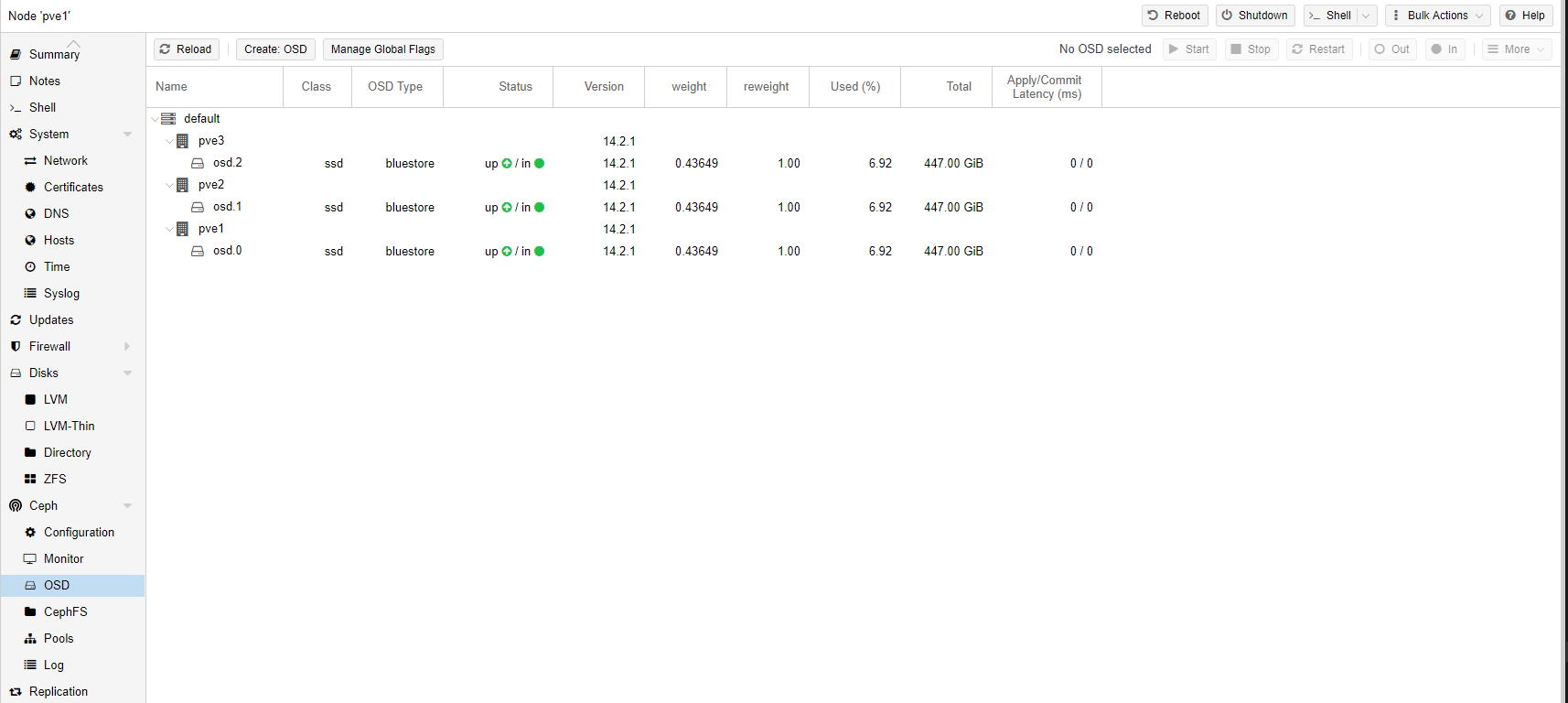
4. Ceph: considerazione sui dischi
Ceph funziona al meglio con una quantità uniforme e distribuita di dischi per nodo. Ad esempio, 4 dischi da 500 GB in ciascun nodo sono migliori di una configurazione mista con un singolo disco da 1 TB e tre dischi da 250 GB.
Nel pianificare il cluster Ceph, in termini di dimensione, è importante prendere in considerazione i tempi di recupero (soprattutto con piccoli cluster).
Per ottimizzare questi tempi, Proxmox consiglia di utilizzare SSD anziché HDD in piccole configurazioni,
In generale, come sapete, gli SSD forniscono più IOP rispetto ai dischi classici a rotazione, ma visto il costo più elevato rispetto agli HDD, potrebbe essere interessante la separazione di pool basata sulla classe (o tipo di disco).
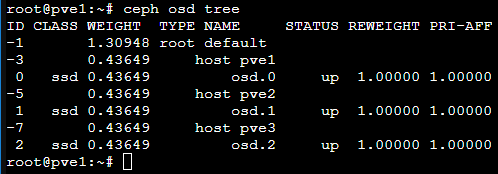
Breve nota per chi ama il command line, un modo veloce e rapido per verificare visivamente il concetto di classe, è quello di dare il comando #ceph osd tree.
Avrete un output, simile a quello mostrato nell’immagine seguente, che riporta le informazioni essenziali sugli OSD tra cui la colonna CLASS, che identifica i dischi (i nostri hanno come valore ssd).
Esiste una possibile configurazione, supportata da Proxmox VE, per velocizzare gli OSD in un ambiente “misto” HDD + SSD: usare un disco più veloce come journal o DB/Write-Ahead-Log (WAL) device.
Questi parametri sono visibili nell’immagine precedente in Ceph: creazione OSD.
Tenete sempre in considerazione che, se si utilizza un disco più veloce per più OSD, sarà necessario bilanciare un corretto equilibrio tra il disco OSD e WAL/DB (o journal), altrimenti il disco veloce rischia di diventare il collo di bottiglia per tutti gli OSDs collegati.
È inoltre necessario bilanciare il numero di OSD e la loro capacità singola.
Una maggiore capacità consente di aumentare la densità di archiviazione, ma significa anche che un singolo errore OSD costringe Ceph a recuperare più dati contemporaneamente.
Ceph: vantaggi nell’utilizzo con Proxmox VE
Ceph è un distributed object store e un file system progettato per fornire prestazioni, affidabilità e scalabilità eccellenti.
Definito anche RADOS Block Devices (RBD) implementa un archivio a livello di blocco ricco di funzionalità; utilizzandolo con Proxmox VE si ottengono i seguenti vantaggi:
- Facile configurazione e gestione con supporto CLI e GUI
- Thin provisioning
- Volumi ridimensionabili
- Distribuito e ridondante (con striping su più OSD)
- Supporto per le snapshots
- Self healing (Autoguarigione – in caso di problemi delle procedure automatiche cercano di risolvere il problema)
- Nessun Single point of failure
- Scalabile al livello exabyte
- Configurazione di più Pools con caratteristiche di ridondanza e prestazioni diverse
- I dati vengono replicati, rendendolo tollerante ai guasti
- Funziona con hardware economico
- Non sono necessari controller RAID hardware
- Open source
Con i recenti sviluppi tecnologici, il nuovo hardware (mediamente) ha CPU potenti e una discreta quantità di RAM, perciò è possibile eseguire i servizi Ceph direttamente sui nodi Proxmox VE. E’ possibile eseguire servizi di archiviazione e VM sullo stesso nodo. Questa tipologia di configurazione è adatta a cluster di piccole e medie dimensioni ed è oggetto di questo lab e articolo.
5. Ceph: simulazione aumento di spazio storage
Durante il lab, come detto in precedenza, abbiamo volutamente inserito un solo SSD per nodo, da assegnare come OSD di Ceph, per verificare cosa accade in caso si abbia la necessità di scalare.
Abbiamo quindi inserito altri 3 SSD, uno per ogni nodo del cluster, con capacità differente (anche se di poco – 512GB) rispetto a quelli già inseriti e poi uno per volta li abbiamo fatti diventare OSD.
In questa immagine potete vedere la schermata di riepilogo dei dischi dentro il nodo (nel nostro caso è uguale per ogni nodo).
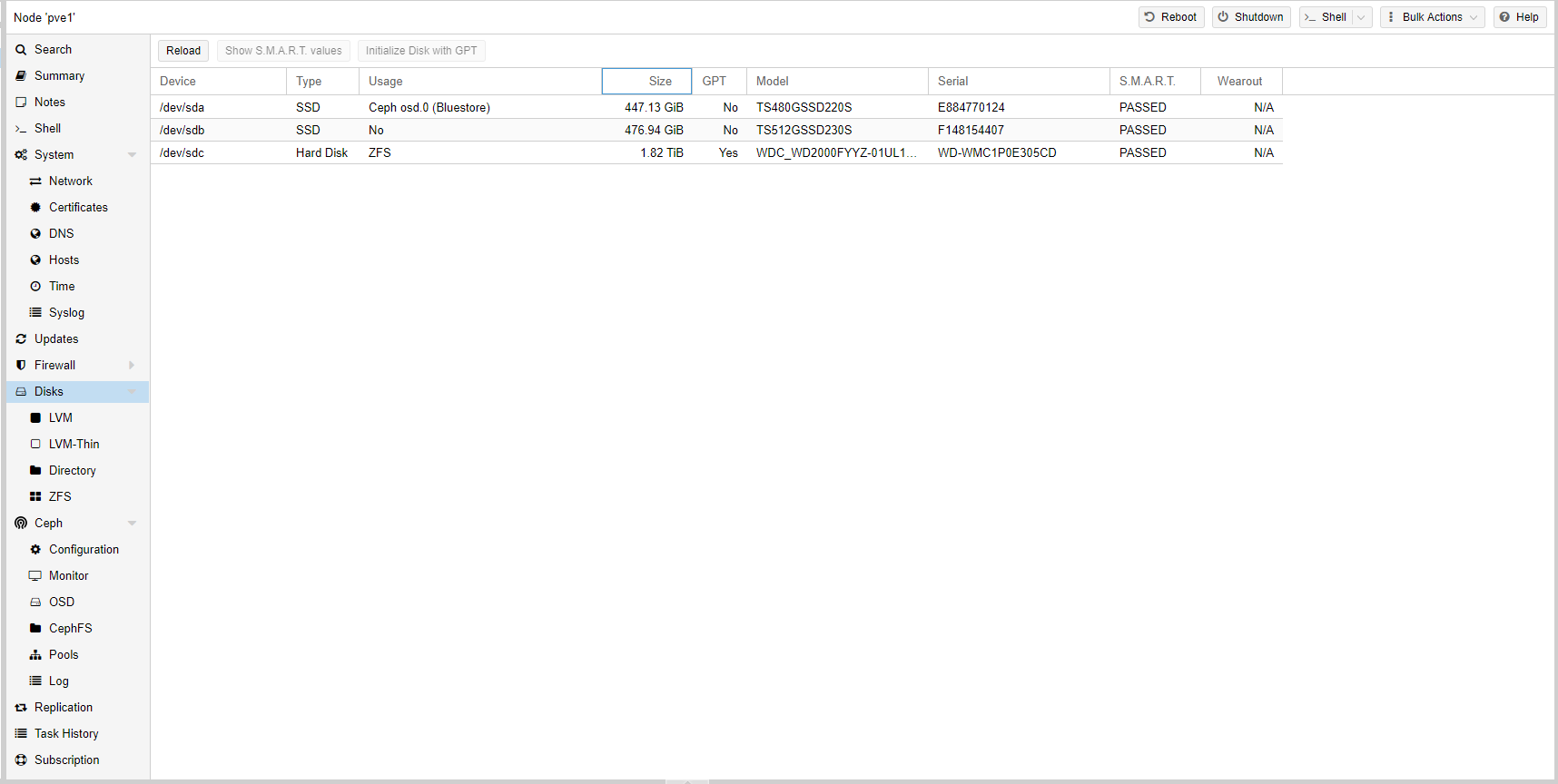
La creazione dei nuovi OSD da assegnare al Pool esistente (ma potete anche creare un nuovo Pool, come detto in precedenza, in base alla classe del disco), è sempre la medesima.
Nel nostro caso, abbiamo lasciato tutti i parametri di default.
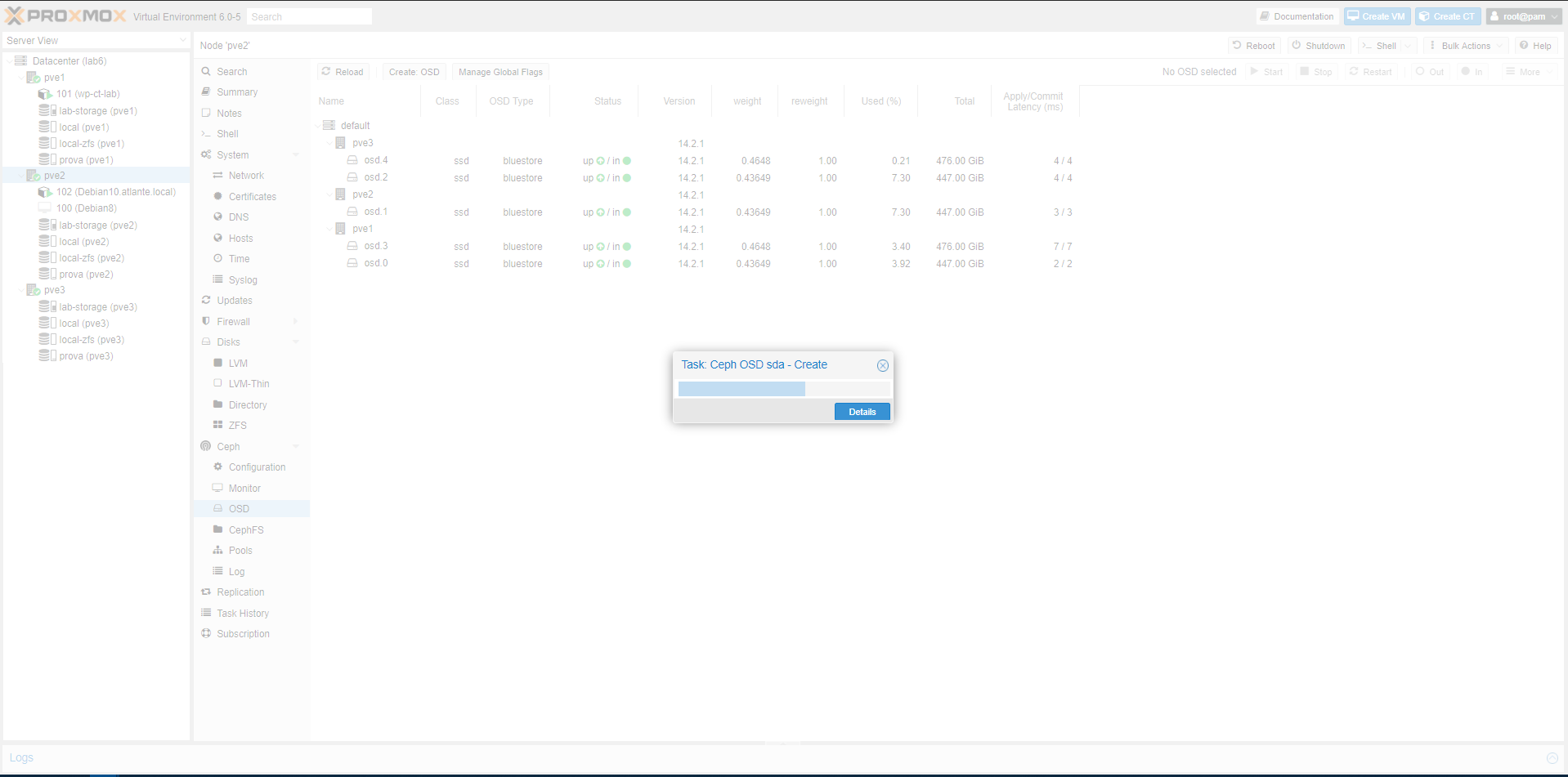
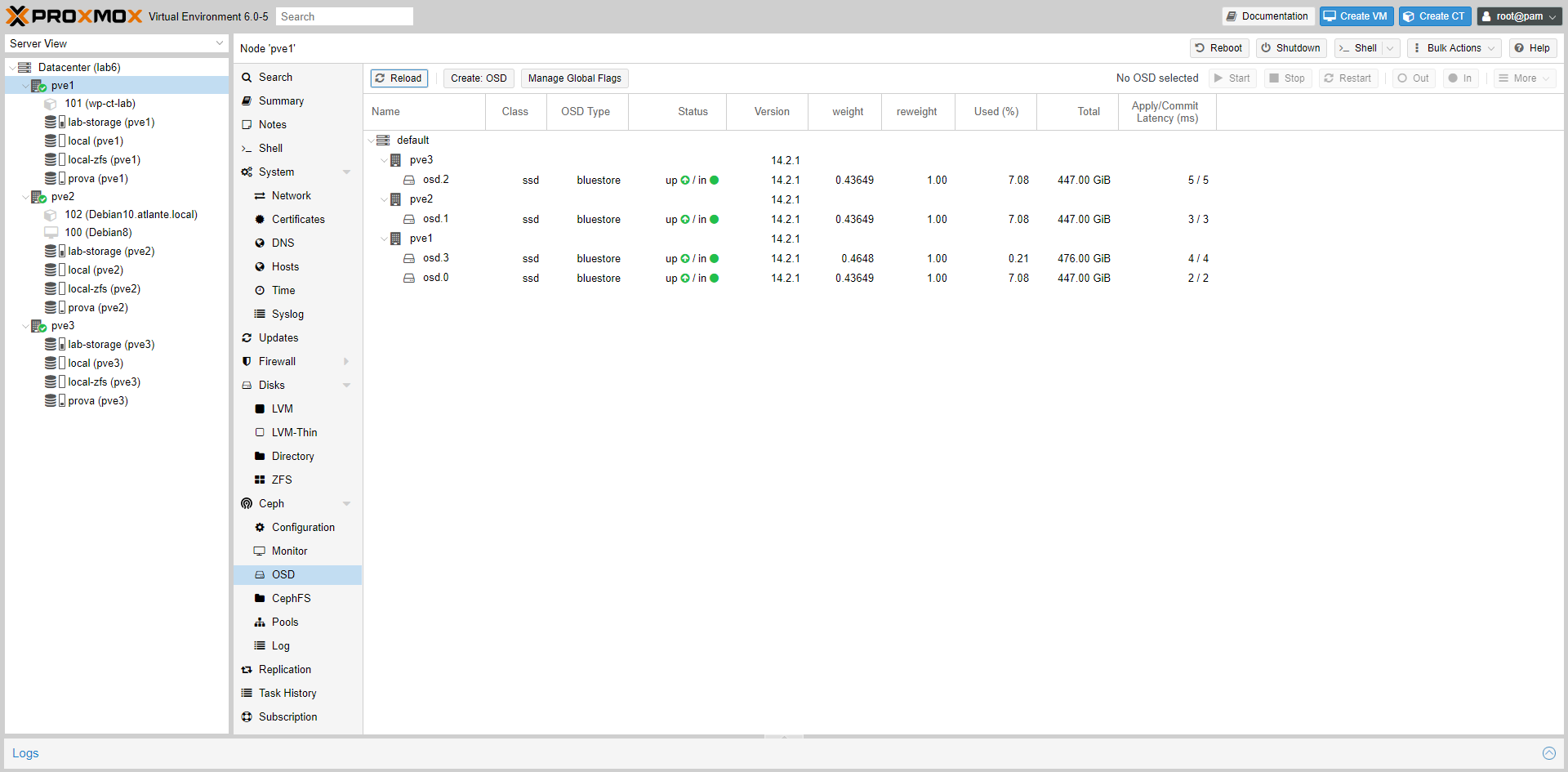
Ogni volta che aggiungiamo un disco, nello status si vedono le operazioni che Ceph compie per poter utilizzare il disco nel pool (o nei pools)
Quando la procedura termina, e se termina correttamente, vedrete qualcosa di simile a quello mostrato in figura (con il numero di OSD “In” aumentato):
NOTA: Non abbiamo avuto evidenza di down o malfunzionamenti delle VM o dei container durante l’ampliamento del pool o durante la creazione dei nuovi OSD
Alcune considerazioni
Nella prima parte del lab, in cui abbiamo inserito 1 solo SSD per nodo come OSD di Ceph, abbiamo creato una VM Debian che esegue uno stress test di 10 ore, e 1 container Ubuntu.
Questo cluster con soli 16GB di RAM e dischi SSD di piccole dimensioni, non lo abbiamo pensato per ambienti di produzione, ma riteniamo doveroso informarvi che nonostante il dimensionamento, si è sempre comportato bene.
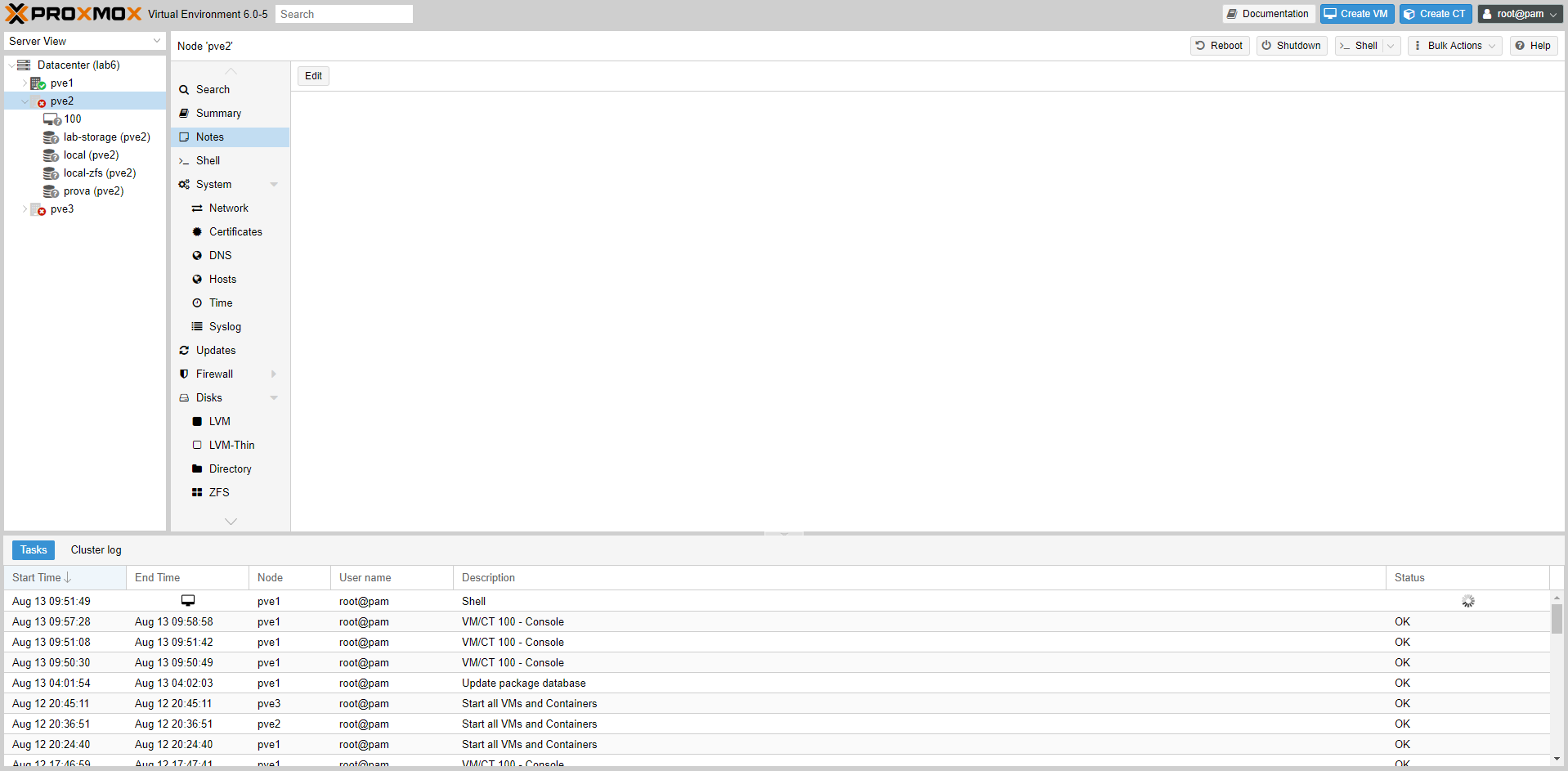
Dopo lo stress test che saturava la memoria, i nodi non si vedevano tra loro graficamente (vedi immagine seguente), ma il cluster e le VM/Container continuavano a funzionare perfettamente.
Il problema era dovuto ad un malfunzionamento del servizio Corosync che non ha impattato sui guests.
Per risolvere abbiamo avviato da cli il servizio di su tutti e tre i nodi:
#systemctl restart corosync.service
6. Simulazione fault disco
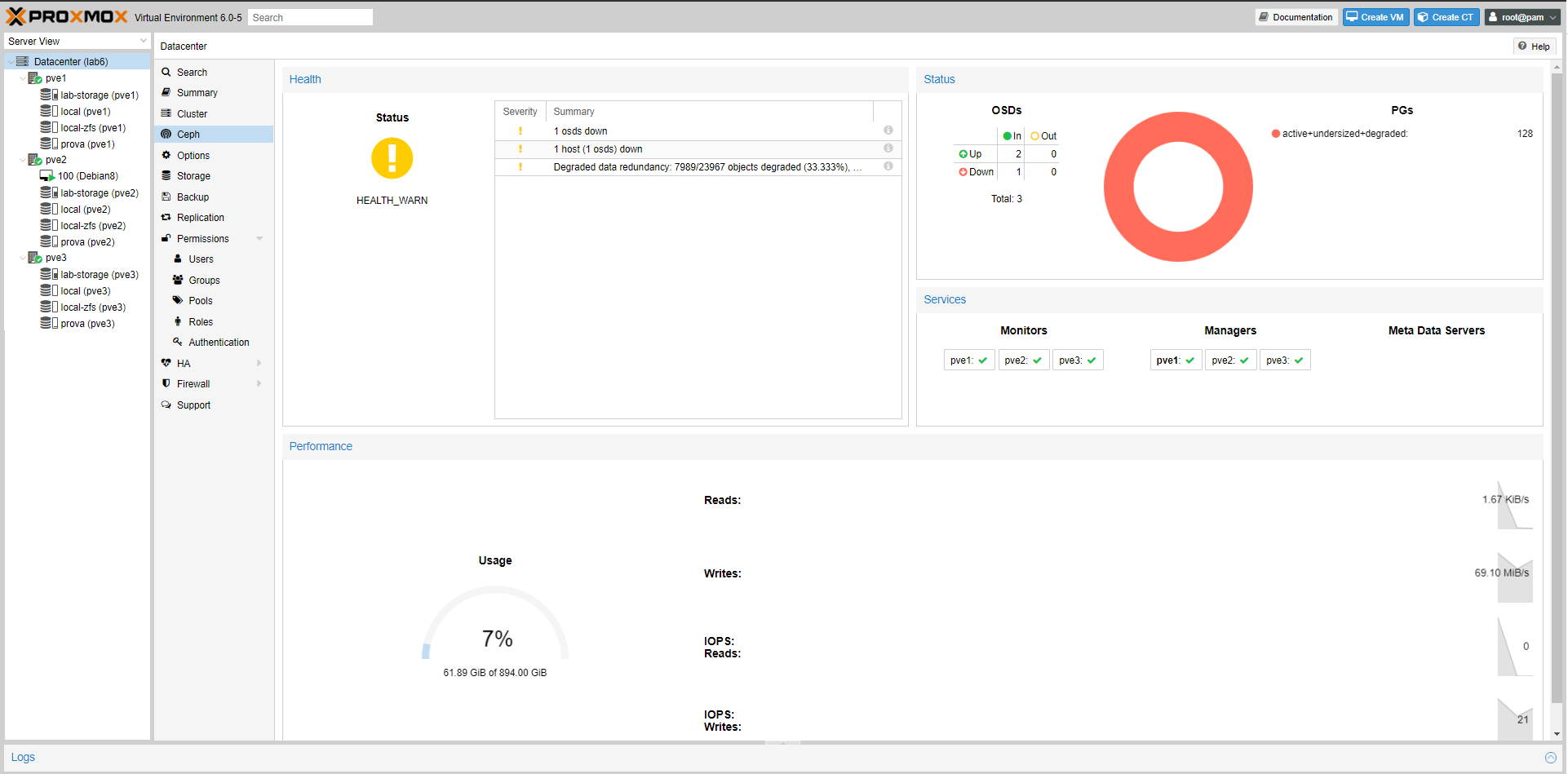
Abbiamo staccato il disco SSD sul PVE2 (dove c’era l’unica VM) per simulare un fault del disco.
La VM parte e funziona ugualmente (vedere immagine seguente – VM100) grazie alle caratteristiche di Ceph (vedi vantaggi sopra).
Nota
Sul pool prova (quello di Ceph), è aumentato lo spazio da 486GB a 650GB (banalmente e senza scendere troppo nel dettaglio, togliendo 1 disco le informazioni che Ceph deve replicare sono diminuite e questo comporta un maggiore spazio su ogni singolo disco).
Nella pagine di status di Ceph, sotto nel riquadro delle Performace –> Usage il valore è invece sceso da 1,31TB a 894GB (questa è la somma delle dimensioni dei dischi che abbiamo fatto diventare OSD per poi creare il pool).
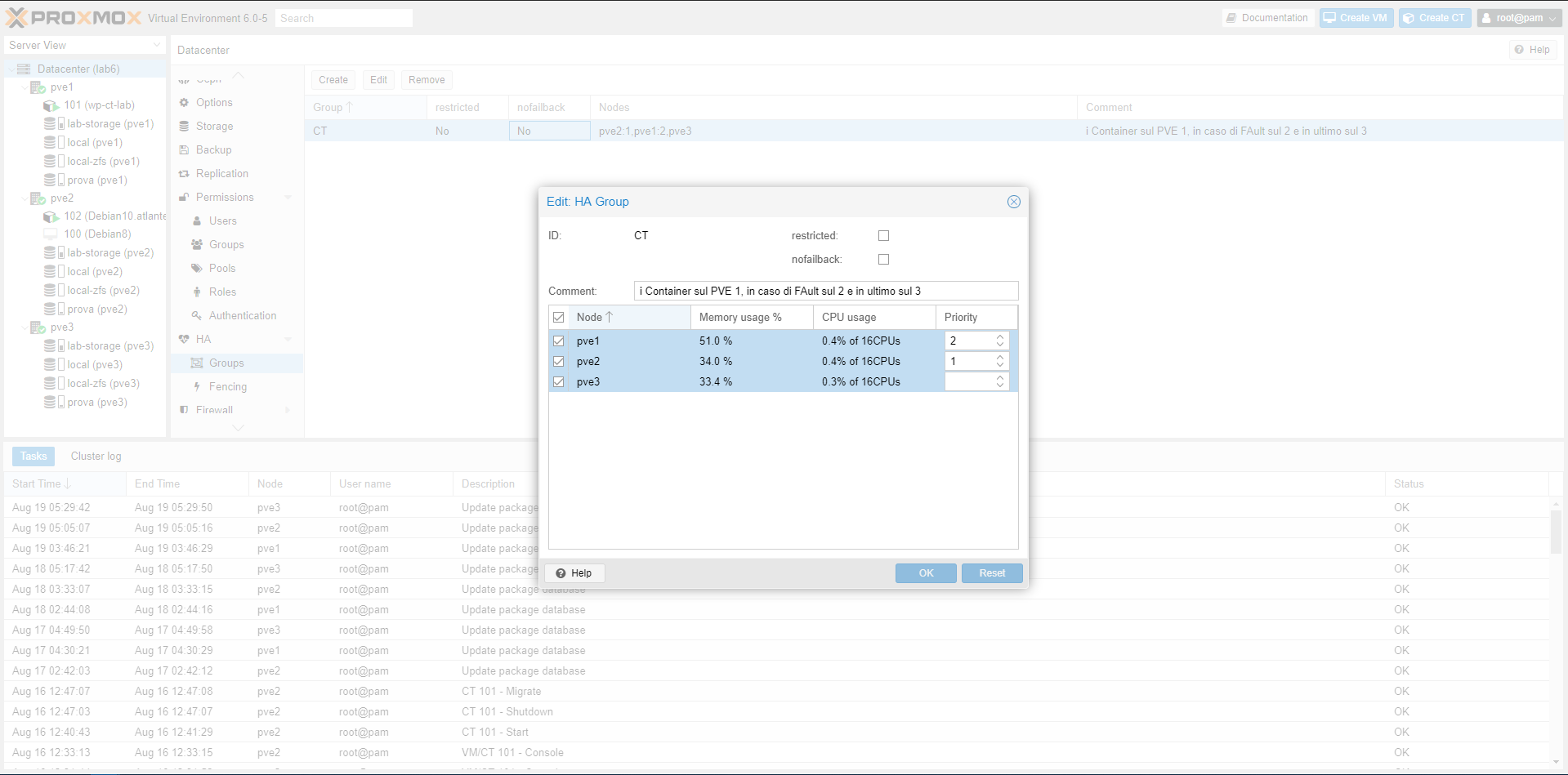
Configurando velocemente le impostazioni di HA, abbiamo simulato il down di un nodo.
Il container, oggetto di questa prova, è stato spostato sul nodo con priorità configurato, e poi ripristinato sul nodo di partenza una volta che il nodo down è tornato on line.
Nelle immagini seguenti, mostriamo brevemente come abbiamo configurato il Group.
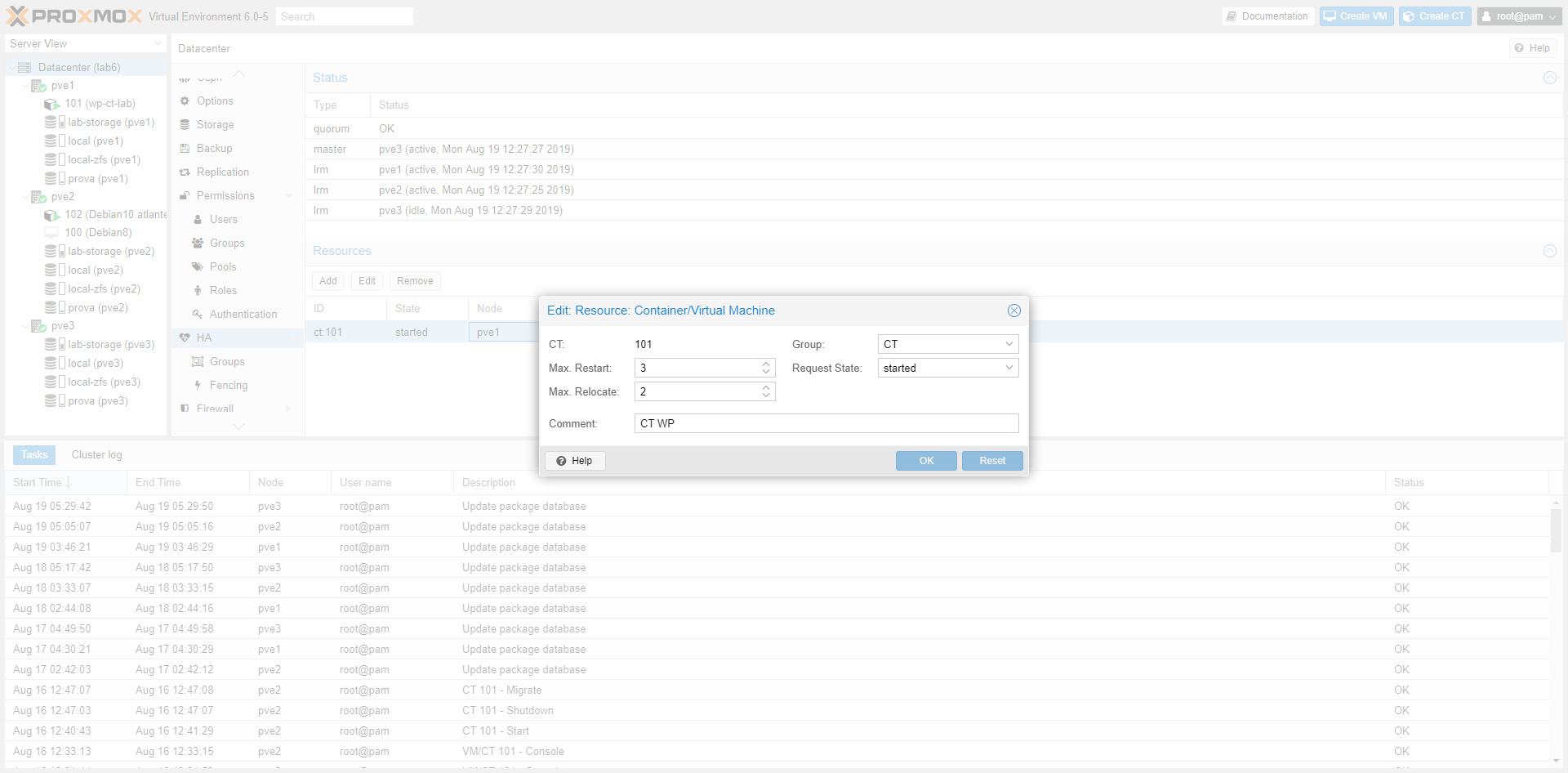
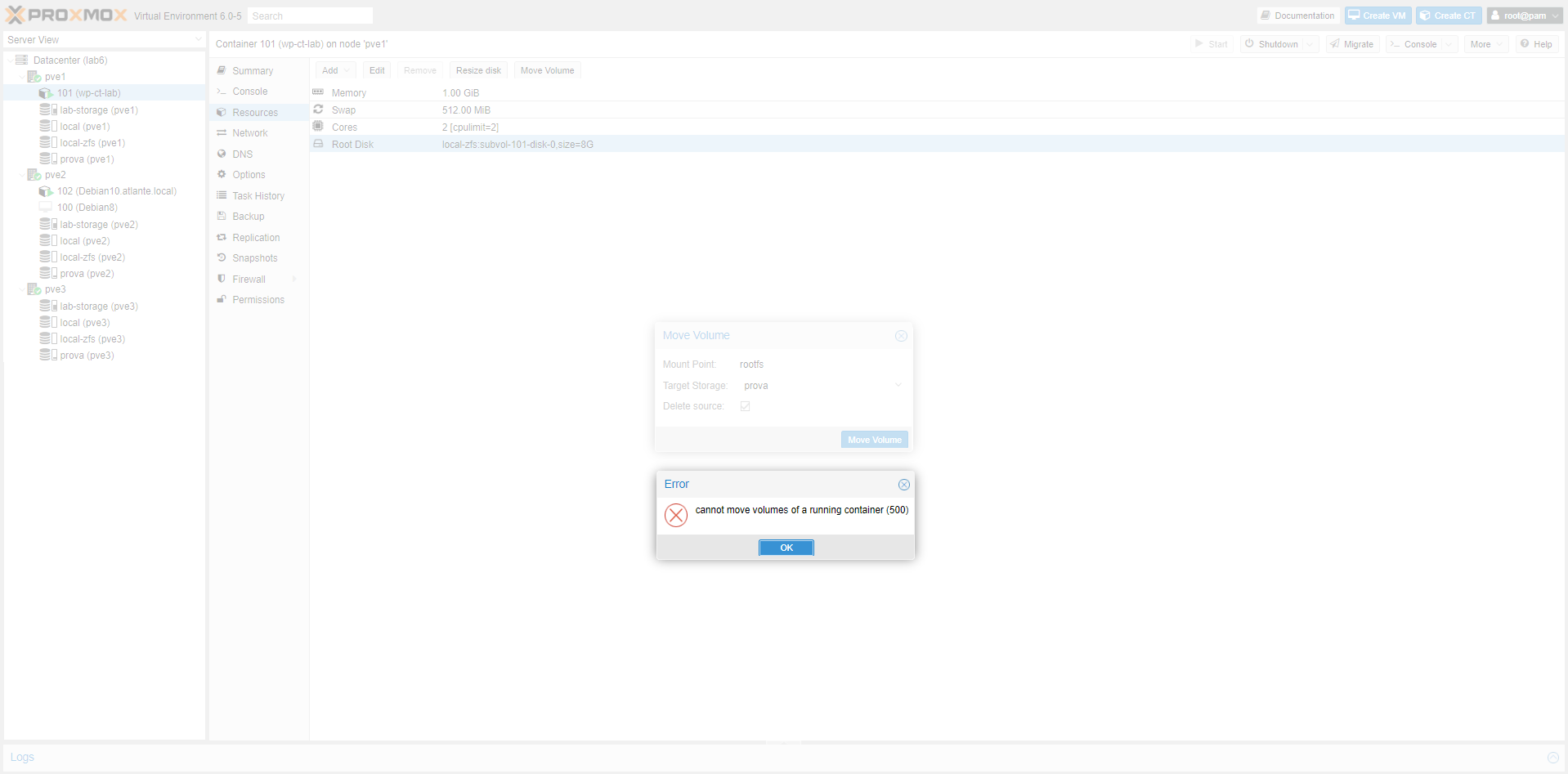
Nota: purtroppo non si può fare uno storage migration, o più semplicemente Move Volume, di un container e/o VM accesa.
Volevamo spostare il container di prova dallo storage local-zfs a Ceph, ecco il risultato:
Ceph sembra un prodotto stabile e davvero intuitivo, se si studiano i valori durante la configurazione (vedere link sotto della documentazione ufficiale).
Offre diversi vantaggi che abbiamo già elencato in precedenza, tuttavia è necessario considerare lo spazio che viene “perso”, e progettare accuratamente lo storage.